Hi there folks, just another Firefox Performance update coming at you here.
These updates are going to shift format slightly. I’m going to start by highlighting the status of some of the projects the Firefox Performance Team (the front-end team working to make Firefox snappy AF), and then go into the grab-bag list of improvements that we’ve seen landing in the tree.
But first a word from our sponsor: arewesmoothyet.com!
This performance update is brought to you by arewesmoothyet.com! On Nightly versions of Firefox, a component called BackgroundHangReporter (or “BHR”) notices anytime the main-threads hang too long, and then collect a stack to send via Telemetry. We’ve been doing this for years, but we’ve never really had a great way of visualizing or making use of the data1. Enter arewesmoothyet.com by Doug Thayer! Initially a fork of perf.html, awsy.com lets us see graphs of hangs on Nightly broken down by category2, and then also lets us explore the individual stacks that have come in using a perf.html-like interface! (You might need to be patient on that last link – it’s a lot of data to download).
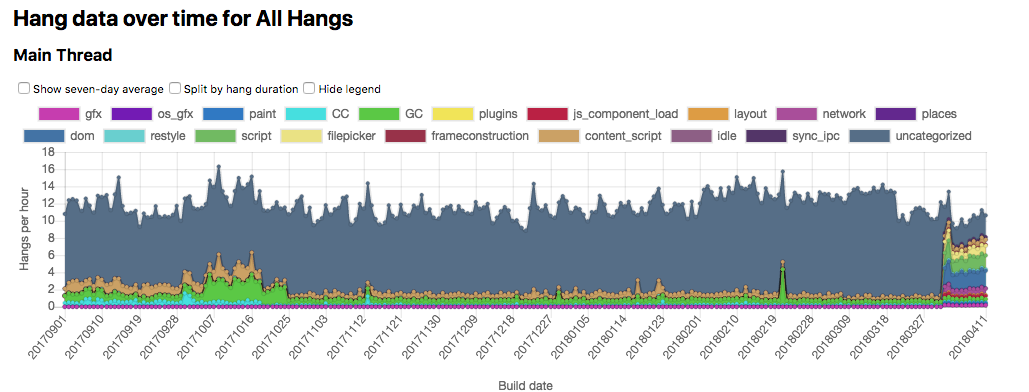
Hot damn! Note the finer-grain categories showing up on April 1st.
Early first blank paint (lead by Florian Quèze)
This is a start-up perceived performance project where early in the executable life-cycle, long before we’ve figured out how to layout and paint the browser UI, we show a white “blank” area on screen that is overtaken with the UI once it’s ready. The idea here is to avoid having the user stare at nothing after clicking on the Firefox icon. We’ll also naturally be working to reduce the amount of time that the blank window appears for users, but our research shows users feel like the browser starts-up faster when we show something rather than nothing. Even if that nothing is… well, mostly nothing. Florian recently landed a Telemetry probe for this feature, made it so that we can avoid initting the GPU process for the blank window, and is in the midst of fixing an issue where the blank window appears for too long. We’re hoping to have this ready to ship enabled on some platforms (ideally Linux and Windows) in Firefox 61.
Faster content process start-up time (lead by Felipe Gomes)
Explorations are just beginning here. Felipe has been examining the scripts that are running for each tab on creation, and has a few ideas on how to both reduce their parsing overhead, as well as making them lazier to load. This project is mostly at the research stage. Expect concrete details on sub-projects and linked bugs soon!
Get ContentPrefService init off of the main thread (lead by Doug Thayer)
This is so, so close to being done. The patch is written and reviewed, but landing it is being stymied by a hard-to-reproduce locally but super-easy-to-reproduce-in-automation shutdown leak during test runs. Unfortunately, the last 10% sometimes takes 90% of the effort, and this looks like one of those cases.
Blocklist improvements (lead by Gijs Kruitbosch)
Gijs is continuing to make our blocklist asynchronous. Recently, he made the getAddonBlocklistEntry method of the API asynchronous, which is a big-deal for start-up, since it means we drop another place where the front-end has to wait for the blocklist to be ready! The getAddonBlocklistState method is next on the list.
As a fun exercise, you can follow the “true” value for the BLOCKLIST_SYNC_FILE_LOAD probe via this graph, and watch while Gijs buries it into the ground.
LRU cache for tab layers (lead by Doug Thayer)
Doug Thayer is following up on some research done a few years ago that suggests that we can make ~95% of our user’s tab switches feel instantaneous by implementing an LRU cache for the painted layers. This is a classic space-time trade-off, as the cache will necessarily consume memory in order to hold onto the layers. Research is currently underway here to see how we can continue to improve our tab switching performance without losing out on the memory advantage that we tend to have over other browsers.
Tab warming (lead by Mike Conley)
Tab warming has been enabled on Nightly for a few weeks, and besides one rather serious glitch that we’ve fixed, we’ve been pretty pleased with the result! There’s one issue on macOS that’s been mulled over, but at this point I’m starting to lean towards getting this shipped on at least Windows for the Firefox 61 release.
Firefox’s Most Wanted: Performance Wins (lead by YOU!)
Before we go into the grab-bag list of performance-related fixes – have you seen any patches landing that should positively impact Firefox’s performance? Let me know about it so I can include it in the list, and give appropriate shout-outs to all of the great work going on! That link again!
Grab-bag time
And now, without further ado, a list of performance work that took place in the tree:
(🌟 indicates a volunteer contributor)
- Rob Wood and Greg Tatum made it so that Nightly profiled Talos jobs now link directly to perf.html from Treeherder!
- Gijs Kruitbosch made it so that we don’t send a sync IPC message every time you keypress with the Findbar open!
- Kris Maglione made it so that we recycle the panel used by WebExtensions, which should make them cheaper to open
- Kartikaya Gupta made it so that painting a TicketMaster page showing the seating diagram of a venue much, much faster
- Florian Quèze made it so that we spend far less resources painting the progress bars for downloads
- Ludovic Hirlimann got rid of the Presentation API system add-on, since it was running some code during start-up on Nightly, but wasn’t actually being used anywhere.
Thanks to all of you! Keep it coming!