I’m writing this in lieu of a traditional Firefox Front-end Performance Update, as I think this will be more useful in the long run than just a snapshot of what my team is doing.
I want to talk about main thread disk access (sometimes referred to more generally as “main thread IO”). Specifically, I’m going to argue that main thread disk access is lethal to program responsiveness. For some folks reading this, that might be an obvious argument not worth making, or one already made ad nauseam — if that’s you, this blog post is probably not for you. You can go ahead and skip most or all of it, if you’d like. Or just skim it. You never know — there might be something in here you didn’t know or hadn’t thought about!
For everybody else, scoot your chairs forward, grab a snack, and read on.
Disclaimer: I wouldn’t call myself a disk specialist. I don’t work for Western Digital or Seagate. I don’t design file systems. I have, however, been using and writing software for computers for a significant chunk of my life, and I seem to have accumulated a bunch of information about disks. Some of that information might be incorrect or imprecise. Please send me mail at mike dot d dot conley at gmail dot com if any of this strikes you as wildly inaccurate (though forgive me if I politely disregard pedantry), and then I can update the post.
The mechanical parts of a computer
If you grab a screwdriver and (carefully) open up a laptop or desktop computer, what do you see? Circuit boards, chips, wires and plugs. Lots of electrons flowing around in there, moving quickly and invisibly.
Notably, there aren’t many mechanical moving parts of a modern computer. Nothing to grease up, nowhere to pour lubricant. Opening up my desktop at home, the only moving parts I can really see are the cooling fans near the CPU and power supply (and if you’re like me, you’ll also notice that your cooling fans are caked with dust and in need of a cleaning).
There’s another moving part that’s harder to see — the hard drive. This might not be obvious, because most mechanical drives (I’ve heard them sometimes referred to as magnetic drives, spinny drives, physical drives, platter drives and HDDs. There are probably more terms.) hide their moving parts inside of the disk enclosure.1
If you ever get the opportunity to open one of these enclosures (perhaps the disk has failed or is otherwise being replaced, and you’re just about to get rid of it) I encourage you to.
As you disassemble the drive, what you’ll probably notice are circular parts, layered on top of one another on a motor that spins them. In between those circles are little arms that can move back and forth. This next image shows one of those circles, and one of those little arms.

Does this remind you of anything? The circular parts remind me of CDs and DVDs, but the arms reaching across them remind me of vinyl players.

The comparison isn’t that outlandish. If you ignore some of the lower-level details, CDs, DVDs, vinyl players and hard drives all operate under the same basic principles:
- The circular part has information encoded on it.
- An arm of some kind is able to reach across the radius of the circular part.
- Because the circular part is spinning, the arm is able to reach all parts of it.
- The end of the arm is used to read the information encoded on it.
There’s some extra complexity for hard drives. Normally there’s more than one spinning platter and one arm, all stacked up, so it’s more like several vinyl players piled on top of one another.
Hard drives are also typically written to as well as read from, whereas CDs, DVDs and vinyls tend to be written to once, and then used as “read-only memory.” (Though, yes, there are exceptions there.)
Lastly, for hard drives, there’s a bit I’m skipping over involving caches, where parts of the information encoded on the spinning platters are temporarily held elsewhere for easier and faster access, but we’ll ignore that for now for simplicity, and because it wrecks my simile.2
So, in general, when you’re asking a computer to read a file off of your hard drive, it’s a bit like asking it to play a tune on a vinyl. It needs to find the right starting place to put the needle, then it needs to put the needle there and only then will the song play.
For hard drives, the act of moving the “arm” to find the right spot is called seeking.
Contiguous blocks of information and fragmentation
Have you ever had to defragment your hard drive? What does that even mean? I’m going to spend a few moments trying to explain that at a high-level. Again, if this is something you already understand, go ahead and skip this part.
Most functional hard drives allow you to do the following useful operations:
- Write data to the drive
- Read data from the drive
- Remove data from the drive
That last one is interesting, because usually when you delete a file from your computer, the information isn’t actually erased from the disk. This is true even after emptying your Trash / Recycling Bin — perhaps surprisingly, the files that you asked to be removed are still there encoded on the circular platters as 1’s and 0’s. This is why it’s sometimes possible to recover deleted files even when it seems that all is lost.
Allow me to explain.
Just like there are different ways of organizing a sock drawer (at random, by colour, by type, by age, by amount of damage), there are ways of organizing a hard drive. These “ways” are called file systems. There are lots of different file systems. If you’re using a modern version of Windows, you’re probably using a file system called NTFS. One of the things that a file system is responsible for is knowing where your files are on the spinning platters. This file system is also responsible for knowing where there’s free space on the spinning platters to write new data to.
When you delete a file, what tends to happen is that your file system marks those sectors of the platter as places where new information can be written to, but doesn’t immediately overwrite those sectors. That’s one reason why sometimes deleted files can be recovered.
Depending on your file system, there’s a natural consequence as you delete and write files of different sizes to the hard drive: fragmentation. This kinda sounds like the actual physical disk is falling apart, but that’s not what it means. Data fragmentation is probably a more precise way of thinking about it.
Imagine you have a sheet of white paper broken up into a grid of 5 boxes by 5 boxes (25 boxes in total), and a box of paints and paintbrushes.

Each square on the paper is white to start. Now, starting from the top-left, and going from left-to-right, top-to-bottom, use your paint to fill in 10 of those boxes with the colour red. Now use your paint to fill in the next 5 boxes with blue. Now do 3 more boxes with yellow.
So we’ve got our colour-filled boxes in neat, organized rows (red, then blue, then yellow), and we’ve got 18 of them filled, and 7 of them still white.
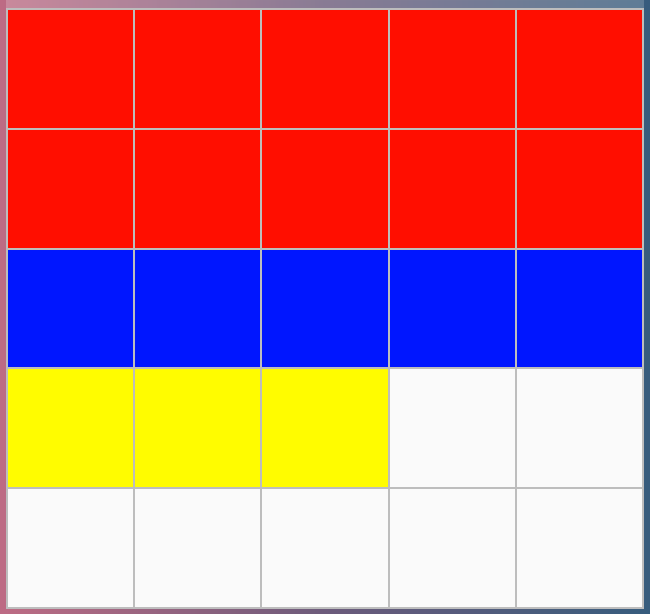
Now let’s say we don’t care about the colour blue. We’re okay to paint over those now with a new colour. We also want to fill in 10 boxes with the colour purple. Hm… there aren’t enough free white boxes to put in that many purple ones, but we have these 5 blue ones we can paint over. Let’s paint over them with purple, and then put the next 5 at the end in the white boxes.
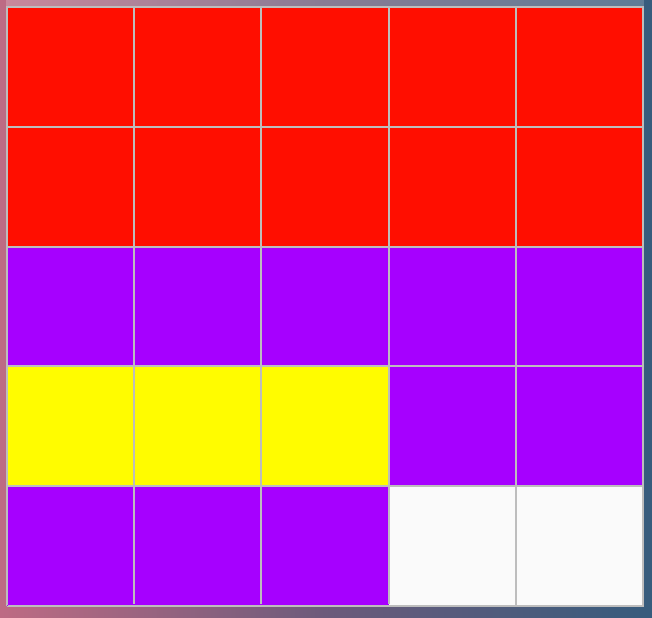
So now 23 of the boxes are filled, we’ve got 2 left at the end that are white, but also, notice that the purple boxes aren’t all together — they’ve been broken apart into two sections. They’ve been fragmented.
This is an incredibly simplified model, but (I hope) it demonstrates what happens when you delete and write files to a hard drive. Gaps open up that can be written to, and bits and pieces of files end up being distributed across the platters as fragments.
This also occurs as files grow. If, for example, we decided to paint two more white boxes red, we’d need to paint the ones at the very end, breaking up the red boxes so that they’re fragmented.
So going back to our vinyl player example for a second — the ideal scenario is that you start a song at the beginning and it plays straight through until the end, right? The more common case with disk drives, however, is you read bits and pieces of a song from different parts of the vinyl: you have to lift and move the arm each time until eventually you have heard the song from start to finish. That seeking of the arm adds overhead to the time it takes to listen to the song from beginning to end.
When your hard drive undergoes defragmentation, what your computer does is try to re-organize your disk so that files are in contiguous sectors on the platters. That’s a fancy way of saying that they’re all in a row on the platter, so they can be read in without the overhead of seeking around to assemble it as fragments.
Skipping that overhead can have huge benefits to your computer’s performance, because the disk is usually the slowest part of your computer.
I’ve skipped over and simplified a bunch of stuff here in the interests of brevity, but this is a great video that gives a crash course on file systems and storage. I encourage you to watch it.
On the relative input / output speeds of modern computing components
I mentioned in the disclaimer at the start of this post that I’m not a disk specialist or expert. Scott Davis is probably a better bet as one of those. His bio lists an impressive wealth of experience, and mentions that he’s “a recognized expert in virtualization, clustering, operating systems, cloud computing, file systems, storage, end user computing and cloud native applications.”
I don’t know Scott at all (if you’re reading this, Hi, Scott!), but let’s just agree for now that he probably knows more about disks than I do.
I’m picking Scott as an expert because of a particularly illustrative analogy that was posted to a blog for a company he used to work for. The analogy compares the speeds of different media that can be used to store information on a computer. Specifically, it compares the following:
- RAM
- The network with a decent connection
- Flash drives
- Magnetic hard drives — what we’ve been discussing up until now.
For these media, the post claims that input / output speed can be measured using the following units:
- RAM is in nanoseconds
- 10GbE Network speed is in microseconds (~50 microseconds)
- Flash speed is in microseconds (between 20-500+ microseconds)
- Disk speed is in milliseconds
That all seems pretty fast. What’s the big deal? Well, it helps if we zoom in a little bit. The post does this by supposing that we pretend that RAM speed happens in minutes.
If that’s the case, then we’d have to measure network speed in weeks.
And if that’s the case, then we’d want to measure the speed of a Flash drive in months.
And if that’s the case, then we’d have to measure the speed of a magnetic spinny disk in decades.
Update (May 23, 2019): My Uncle Mark, who also works in computing, sent me links that show similar visualizations of computing latency: this one has a really excellent infographic, and this one has more discussion. These articles highlight network latency as the worst offender, which is true especially when the quality of service is low, but I’m mostly writing this post for folks who hack on Firefox where the vast majority of networking occurs off of the main thread.
I wish I had some ACM paper, or something written by a computer science professor that I could point to you to bolster the following claim. I don’t, not because one doesn’t exist, but because I’m too lazy to look for one. I hope you’ll forgive me for that, but I don’t think I’m saying anything super controversial when I say:
In the common case, for a personal computer, it’s best to assume that reading and writing to the disk is the slowest operation you can perform.
Sure, there are edge cases where other things in the system might be slower. And there is that disk cache that I breezed over earlier that might make reading or writing cheaper. And sometimes the operating system tries to do smart things to help you. For now, just let it go. I’m making a broad generalization that I think covers the common cases, and I’m talking about what’s best to assume.
Single and multi-threaded restaurants
When I try to describe threading and concurrency to someone, I inevitably fall back to the metaphor of cooks in a kitchen in a restaurant. This is a special restaurant where there’s only one seat, for a single customer — you, the user.
Single-threaded programs
Let’s imagine a restaurant that’s very, very small and simple. In this restaurant, the cook is also acting as the waiter / waitress / server. That means when you place your order, the server / cook goes into the kitchen and makes it for you. While they’re gone, you can’t really ask for anything else — the server / cook is busy making the thing you asked for last.
This is how most simple, single-threaded programs work—the user feeds in requests, maybe by clicking a button, or typing something in, maybe something else entirely—and then the program goes off and does it and returns some kind of result. Maybe at that point, the program just exits (“The restaurant is closed! Come back tomorrow!”), or maybe you can ask for something else. It’s really up to how the restaurant / program is designed that dictates this.
Suppose you’re very, very hungry, and you’ve just ordered a complex five-course meal for yourself at this restaurant. Blanching, your server / cook goes off to the kitchen. While they’re gone, nobody is refilling your water glass or giving you breadsticks. You’re pretty sure there’s activity going in the kitchen and that the server / cook hasn’t had a heart attack back there, but you’re going to be waiting a looooong time since there’s only one person working in this place.
Maybe in some restaurants, the server / cook will dash out periodically to refill your water glass, give you some breadsticks, and update you on how things are going, but it sure would be nice if we gave this person some help back there, wouldn’t it?
Multi-threaded programs
Let’s imagine a slightly different restaurant. There are more cooks in the kitchen. The server is available to take your order (but is also able to cook in the kitchen if need be), and you make your request from the menu.
Now suppose again that you order a five-course meal. The server goes to the kitchen and tells the cooks what you just ordered. In this restaurant, suppose the kitchen staff are a really great team and don’t get in each other’s way3, so they divide up the order in a way that makes sense and get to work.
The server can come back and refill your water glass, feed you breadsticks, perhaps they can tell you an entertaining joke, perhaps they can take additional orders that won’t take as long. At any rate, in this restaurant, the interaction between the user and the server is frequent and rarely interrupted.
The waiter / waitress / server is the main thread
In these two examples, the waiter / waitress / server is what is usually called the main thread of execution, which is the part of the program that the user interacts with most directly. By moving expensive operations off of the main thread, the responsiveness of the program increases.
Have you ever seen the mouse turn into an hourglass, seen the “This program is not responding” message on Windows? Or the spinny colourful pinwheel on macOS? In those cases, the main thread is off doing something and never came back to give you your order or refill your water or breadsticks — that’s how it generally manifests in common operating systems. The program seems “unresponsive”, “sluggish”, “frozen”. It’s “hanging”, or “stuck”. When I hear those words, my immediate assumption is that the main thread is busy doing something — either it’s taking a long time (it’s making you your massive five course meal, maybe not as efficiently as it could), or it’s stuck (maybe they fell down a well!).
In either case, the general rule of thumb to improving program responsiveness is to keep the server filling the user’s water and breadsticks by offloading complex things on the menu to other cooks in the kitchen.
Accessing the disk on the main thread
Recall that in the common case, for a personal computer, it’s best to assume that reading and writing to the disk is the slowest operation you can perform. In our restaurant example, reading or writing to the disk on the main thread is a bit like having your server hop onto their bike and ride out to the next town over to grab some groceries to help make what you ordered.
And sometimes, because of data fragmentation (not everything is all in one place), the server has to search amongst many many shelves all widely spaced apart to get everything.
And sometimes the grocery store is very busy because there are other restaurants out there that are grabbing supplies.
And sometimes there are police checks (anti-virus / anti-malware software) occurring for passengers along the road, where they all have to show their IDs before being allowed through.
It’s an incredibly slow operation. Hopefully by the time the server comes back, they don’t realize they have to go back out again to get more, but they might if they didn’t realize they were missing some more ingredients.4
Slow slow slow. And unresponsive. And a great way to lose a hungry customer.
For super small programs, where the kitchen is well stocked, or the ride to the grocery store doesn’t need to happen often, having a single-thread and having it read or write is usually okay. I’ve certainly written my fair share of utility programs or scripts that do main thread disk access.
Firefox, the program I spend most of my time working on as my job, is not a small program. It’s a very, very, very large program. Using our restaurant model, it’s many large restaurants with many many cooks on staff. The restaurants communicate with each other and ship food and supplies back and forth using messenger bikes, to provide to you, the customer, the best meals possible.
But even with this large set of restaurants, there’s still only a single waiter / waitress / server / main thread of execution as the point of contact with the user.
Part of my job is to help organize the workflows of this restaurant so that they provide those meals as quickly as possible. Sending the server to the grocery store (main thread disk access) is part of the workflow that we absolutely need to strike from the list.
Start-up main-thread disk access
Going back to our analogy, imagine starting the program like opening the restaurant. The lights go on, the chairs come off of the tables, the kitchen gets warmed up, and prep begins.
While this is occurring, it’s all hands on deck — the server might be off in the kitchen helping to do prep, off getting cutlery organized, whatever it takes to get the restaurant open and ready to serve. Before the restaurant is open, there’s no point in having the server be idle, because the customer hasn’t been able to come in yet.
So if critical groceries and supplies needed to open the restaurant need to be gotten before the restaurant is open, it’s fine to send the server to the store. Somebody has to do it.
For Firefox, there are various things that need to take place before we can display any UI. At that point, it’s usually fine to do main-thread disk access, so long as all of the things being read or written are kept to an absolute minimum. Find how much you need to do, and reduce it as much as possible.
But as soon as UI is presented to the user, the restaurant is open. At that point, the server should stay off their bike and keep chatting with the customer, even if the kitchen hasn’t finished setting up and getting all of their supplies. So to stay responsive, don’t do disk access on the main thread of execution after you’ve started to show the user some kind of UI.
Disk contention
There’s one last complication I want to capture here with our restaurant example before I wrap up. I’ve been saying that it’s important to send anyone except the server to the grocery store for supplies. That’s true — but be careful of sending too many other people at the same time.
Moving disk access off of the main thread is good for responsiveness, full stop. However, it might do nothing to actually improve the overall time that it takes to complete some amount of work. Put it another way: just because the server is refilling your glass and giving you breadsticks doesn’t mean that your five-course meal is going to show up any faster.
Also, disk operations on magnetic drives do not have a constant speed. Having the disk do many things at once within a single program or across multiple programs can slow the whole set of operations down due to the overhead of seeking and context switching, since the operating system will try to serve all disk requests at once, more or less.5
Disk contention and main thread disk access is something I think a lot about these days while my team and I work on improving Firefox start-up performance.
Some questions to ask yourself when touching disk
So it’s important to be thoughtful about disk access. Are you working on code that touches disk? Here are some things to think about:
Is UI visible, and responsiveness a goal?
If so, best to move the disk access off of the main-thread. That was the main thing I wanted to capture, and I hope I’ve convinced you of that point by now.
Does the access need to occur?
As programs age and grow and contributors come and go, sometimes it’s important to take a step back and ask, “Are the assumptions of this disk access still valid? Does this access need to happen at all?” The fastest code is the code that doesn’t run at all.
What else is happening during this disk access? Can disk access be prioritized more efficiently?
This is often trickier to answer as a program continues to run. Thankfully, tools like profilers can help capture recordings of things like disk access to gain evidence of simultaneous disk access.
Start-up is a special case though, since there’s usually a somewhat deterministic / reliably stable set of operations that occur in the same way in roughly the same order during start-up. For start-up, using a tool like a profiler, you can gain a picture of the sorts of things that tend to happen during that special window of time. If you notice a lot of disk activity occurring simultaneously across multiple threads, perhaps ponder if there’s a better way of ordering those operations so that the most important ones complete first.
Can we reduce how much we need to read or write?
There are lots of wonderful compression algorithms out there with a variety of performance characteristics that might be worth pondering. It might be worth considering compressing the data that you’re storing before writing it so that the disk has to write less and read less.
Of course, there’s compression and decompression overhead to consider here. Is it worth the CPU time to save the disk time? Is there some other CPU intensive task that is more critical that’s occurring?
Can we organize the things that we want to read ahead of time so that they’re more likely to be read contiguously (without seeking the disk)?
If you know ahead of time the sorts of things that you’re going to be reading off of the disk, it’s generally a good strategy to store them in that read order. That way, in the best case scenario (the disk is defragmented), the read head can fly along the sectors and read everything in, in exactly the right order you want them. If the user has defragmented their disk, but the things you’re asking for are all out of order on the disk, you’re adding overhead to seek around to get what you want.
Supposing that the data on the disk is fragmented, I suspect having the files in order anyways is probably better than not, but I don’t think I know enough to prove it.
Flawed but useful
One of my mentors, Greg Wilson, likes to say that “all models are flawed, but some are useful”. I don’t think he coined it, but he uses it in the right places at the right times, and to me, that’s what counts.
The information in this post is not exhaustive — I glossed over and left out a lot. It’s flawed. Still, I hope it can be useful to you.
Thanks
Thanks to the following folks who read drafts of this and gave feedback:
- Mandy Cheang
- Emily Derr
- Gijs Kruitbosch
- Doug Thayer
- Florian Quèze
There are also newer forms of disks called Flash disks and SSDs. I’m not really going to cover those in this post. ↩
The other thing to keep in mind is that the disk cache can have its contents evicted at any time for reasons that are out of your control. If you time it right, you can maybe increase the probability of a file you want to read being in the cache, but don’t bet the farm on it. ↩
When writing multi-threaded programs, this is much harder than it sounds! Mozilla actually developed a whole new programming language to make that easier to do correctly. ↩
Keen readers might notice I’m leaving out a discussion on Paging. That’s because this blog post is getting quite long, and because it kinda breaks the analogy a bit — who sends groceries back to a grocery store? ↩
I’ve never worked on an operating system, but I believe most modern operating systems try to do a bunch of smart things here to schedule disk requests in efficient ways. ↩