Whoops
First off, an apology. I’ve fallen behind on these posts, and that’s not good – the iron has cooled, and I was taught to strike it while it was hot. I was hit with classic blogcrastination.
Secondly, another apology – I made a few errors in my last post, and I’d like to correct them:
- It’s come to my attention that I played a little fast and loose with the notions of “global history” and “session history”. They’re really two completely different things. Specifically, global history is what populates the AwesomeBar. Global history’s job is to remember every site you visit, regardless of browser window or tab. Session history is a different beast altogether – session history is the history inside the back-forward buttons. Every time you click on a link from one page, and travel to the next, you create a little nugget of session history. And when you click the back button, you move backwards in that session history. That’s the difference between the two – “like chalk and cheese”, as NeilAway said when he brought this to my attention.
- I also said that the docshell/ folder was created on Travis’s first landing on October 15th, 1998. This is not true – the docshell/ folder was created several months earlier, in this commit by “kipp”, dated July 18, 1998.
I’ve altered my last post to contain the above information, along with details on what I found in the time of that commit to Travis’s first landing. Maybe go back and give that a quick skim while I wait. Look for the string “correction” to see what I’ve changed.
I also got some confirmation from Travis himself over Twitter regarding my last post:
@mike_conley Looks like general right flow as far as 14 years ago memory can aid. 🙂 Many context points surround…
@mike_conley 1) At that time, Mozilla was still largely in walls of Netscape, so many reviews/ alignment happened in person vs public docs.
@mike_conley 2) XPCOM ideas were new and many parts of system were straddling C++ objects and Interface models.
@mike_conley 3) XUL was also new and boundaries of what rendering belonged in browser shell vs. general rendering we’re [sic] being defined.
@mike_conley 4) JS access to XPCOM was also new driving rethinking of JS control vs embedding control.
@mike_conley There was a massive unwinding of the monolith and (re)defining of what it meant to build a browser inside a rendered chrome.
It’s cool to hear from the guy who really got the ball rolling here. The web is wonderful!
Finally, one last apology – this is a long-ass blog post. I’ve been working on it off and on for about 3 months, and it’s gotten pretty massive. Strap yourself into whatever chair you’re near, grab a thermos, cancel any appointments, and flip on your answering machine. This is going to be a long ride.

Oh come on, it’s not that bad, right? … right?
OK, let’s get back down to it. Where were we?
2005
A frame spoofing bug
Ah, yes – 2005 had just started. This was just a few weeks after a community driven effort put a full-page ad for Firefox in the New York Times. Only a month earlier, a New York Times article highlighted Firefox, and how it was starting to eat into Internet Explorer’s market share.
So what was going on in DocShell? Here are the bits I found most interesting. They’re kinda few and far between, since DocShell appears to have stabilized quite a bit by now. Mostly tiny bugfixes are landed, with the occasional interesting blip showing up. I guess this is a sign of a “mature” section of the codebase.
I found this commit on January 11th, 2005 pretty interesting. This patch fixes bug 103638 (and bug 273699 while it’s at it). What was going on was that if you had two Firefox windows open, both with <frameset>’s, where two <frames> had the same name attribute, it was possible for links clicked in one to sometimes open in the other. Youch! That’s a pretty serious security vulnerability. jst’s patch added a bunch of checks and smarter selection for link targets.
One of those new checks involved adding a new static function called CanAccessItem to nsDocShell.cpp, and having FindItemWithName (an nsDocShell instance method used to find some child nsIDocShellTreeItem with a particular name) take a new parameter of the “original requestor”, and ensuring that whichever nsIDocShellTreeItem we eventually landed on with the name that was requested passes the CanAccessItem test with the original requestor.
DocShell and session history
There are two commits, one on January 20th, 2005, and one on January 30th, 2005, both of which fix different bugs, but are interrelated and I want to talk about them for a second.
The first commit, for bug 277224, fixes a problem where if we change location to an anchor located within a document within a <script> tag, we stop loading the page content because the browser thinks we’re about to start loading a document at a different location. bz fixed the more common case of location change via setting document.location.href in bug 233963. Bug 277224 is interested in the case where document.location.href is modified with the .replace() method.
The solution that bz uses is to add new flags for nsIDocShellLoadInfo, which gives more power in how to stop loading a page. Specifically, it adds a LOAD_FLAGS_STOP_CONTENT flag which allows the caller to stop the rendering of content and all network activity (where the default was just to stop network activity). I believe what happens is that replace() causes an InternalLoad to kick off, and we need content rendering to be stopped in order for this new load to take over properly. That’s my reading on the situation, anyhow. If bz or anybody else examining that patch has another interpretation, please let me know!
So what about the commit on January 30th? Well that one also involves anchors. What was happening was that if we browsed to some page, and then clicked a link that scrolled us to an anchor in that page, clicking back would reload the entire document off the cache again, when we really just need to restore the old scroll position.
The patch to fix this basically detected the case where we were going back from an anchor to a non-anchor but had the same URL, and allowed a scroll in that case.
So how is this related to the commit for bug 277224? Well, what it shows is that at this time, DocShell was responsible for not just knowing how to load a document and subdocuments, but also about the user’s state in that document – specifically, their scroll position. It also more firmly establishes the link between DocShell and Session History – as DocShell traverses pages, it communicates with Session History to let it know about those transitions, and refers to it when traveling backwards and forwards, and when restoring state for those session history entries.
I just thought that was kinda neat to know.
Window pains
On February 8th, 2005, danm landed a patch to fix bug 278143, which was a bug that caused windows opened with window.open to open in a new window if they had no target specified. This wouldn’t normally be a problem, except that this could override a user preference to open those new windows in new tabs instead. So that was bad.
This was simply a matter of adding a check for the null case for the target window name in nsWindowWatcher. No big deal.
The reason I bring this code up, is because I find it familiar – I brushed by it somewhat when I was working on making it possible to open new windows for multi-process Firefox.
Semi-related (because of the “popup” nature of things), is a commit on February 23rd, 2005. This one is for bug 277574, which makes it so that modal HTTP auth prompts focus the tabs that spawn them. This patch works by making sure HTTP auth prompts fire the same DOMWillOpenModalDialog and DOMModalDialogClosed events that tabbrowser listens for to focus tabs.
The copy and the cache
On March 11, 2005, NeilAway landed a commit to add the “Copy Image” command item to the context menu. This was for bug 135300.
What’s interesting here is that “Copy Image Location” was already in the context menu, and in the bug, it looks like there’s some contention over whether or not to keep it. It seems that right around here, the solution they go with is to copy both the image and the image location to the clipboard, and mark each copy with the right “flavours”, so that if you were to paste to a program or field that accepted an “image” flavour, like Photoshop, you’d get the image. If you pasted to a program or field that accepted a “text” flavour, like Notepad, you’d get the image URL.
That’s the solution that was landed, anyhow. Notice that nowadays, Firefox has context menu items that allow users to copy just the image, and just the URL – so at some point, this approach was deemed wanting. I’ll keep my eye out to see if I can find out where that happened, and why. If anybody knows, please comment!
On April 28, 2005, roc landed a commit for bug 240276, which splits up something called “nsGfxScrollFrame” into two things – nsHTMLScrollFrame and nsXULScrollFrame. It seems like, up until this point, layout for both XUL and HTML scrollable frames were handled by the same code. This meant that we were using XUL box-model style layout for HTML, and XUL layout is… well… kind of tricky to work with. This patch helped to further distance our HTML rendering from our XUL rendering. As for how this affected DocShell, the patch removed some scroll calculations from DocShell, where they probably didn’t belong in the first place.
On May 4, 2005, Brian Ryner landed a patch which made it possible to move back and forward across web pages much more quickly. This was for bug 274784, and a key part of a project called “fastback”. When you view a web page, a DocShell is put in charge of requesting network activity to retrieve the document source, and then passing that source onto an appropriate nsIContentViewer. Up until Brian’s patch, it looks like every nsIContentViewer was just getting thrown away after browsing away from a page. His patch made it possible to store a certain number of these nsIContentViewers in the session history of the window, and then retrieve it when we browse back or forward to the associated page. This is a textbook trade-off between speed (the time to instantiate and initialize an nsIContentViewer) and space (stored nsIContentViewers consume memory). And it looks like the trade-off paid-off! We still cache nsIContentViewers to this day. What’s interesting about Brian’s patch is that it exposes an about:config preference1 for setting how many content viewers are allowed to be cached2. As DocShell seems to go hand in hand with session history, it’s not surprising that Brian’s patch touches DocShell code.
about:neterror arrives, Inner and Outer windows appear, and then Session History gets all snuggly with DocShell
On July 14th of 2005, bsmedberg landed a patch to add about:neterror pages, and close a privilege-escalation security vulnerability. Up until this point, network error pages were shown by browsing the DocShell to chrome URLs3, but this allowed certain types of attacks which load iframes resolving to network error pages to potentially gain chrome privileges4.
So instead of going to a chrome URL, the patch causes DocShell to internally load about:neterror5 The great news about this about:neterror page is that it has restricted permissions, so that security hole got plugged.
On July 30th, 2005, jst landed a patch to introduce the notion of inner and outer windows for bug 296639. Inner and outer windows has confused me for a while, but I think I’ve somewhat wrapped my head around it. This document helped.
The idea goes something like this:
The thing that is showing you web content can be considered the outer window – so that could be a browser tab, or an iframe, for example. The inner window is the content being displayed – it’s transitory, and goes away as you browse the web via the outer window.
The outer window then has a notion of all of the inner windows it might contain, and the inner window (via Javascript) gets a handle on the outer window via the window global.
So, for example, if you call window.open, the returned value is an outer window. Methods that you call on that outer window are then forwarded to the inner window.
I hope I got that right. I was originally trying to piece together the meaning of all of it by reading this WHATWG spec describing browsing context, and that was pretty slow going. The MDN page seemed much more clear.
Please comment with corrections if I got any of that wrong.
I’m not entirely sure, but based entirely on instinct and experience, I’m inclined to believe there are interesting security effects of this split. It seems to add a bit more of a membrane6 between web content and the physical window.
Anyhow, jst’s change was pretty monumental. It’s for bug 296639 if you want to read up more about it.
A semi-related change was landed on August 12th by mrbkab, where the entire inner window is stashed in the bfcache (as opposed to what we were doing before, which looks like serialization and deserialization of window state). That was for bug 303267, and sounds related to the fast back and forward caching work that Brian Ryner was working on back in May.
On August 18th of 2005, radha landed the first in the series of patches to session history. Unfortunately, the commit message for this patch doesn’t have a bug number, so I had some trouble tracking down what this work is for. I think this work is for bug 230363, and is actually a copy of interfaces from xpfe/components/shistory/public to docshell/shistory/public. Like I mentioned earlier, DocShell and session history are closely linked, so I suppose it makes sense to put the session history code under docshell/. Later that day, another patch copies the nsISHistoryListener interfaces over as well. Finally, a patch landed to build those interfaces from their new locations, and removes xpfe/components/shistory from Makefile.in. The bug for that last change is bug 305090.
Last bit of 2005
On August 22 of 2005, mrbkap landed a patch that changed how content viewer caching worked. There’s a special page in Firefox called about:blank – if you go to that page right now, you’re going to get a blank page. Some people like to set that as their home page or new tab page, as it is (or should be) very lightweight to load. That page is also special because, from what I can tell, when a new tab or window opens, it’s initially pointing at about:blank before it goes to the requested destination. Before this patch, we used to cache that about:blank content viewer in session history. We didn’t put an entry in the back-forward cache for about:blank though7, so that was a useless cache and a waste of memory. mrbkap’s patch made DocShell check to see if the page it was traveling to was going to re-use the current inner window, and if so, it’d skip caching it. Memory win!
That was the last thing I found interesting in 2005. On to 2006!
Preferences and threads…
On February 7th, 2006, bz landed a patch that made it possible for embedders to override where popup windows get opened.
There are preferences in Firefox that allow you to tweak how web content is able to open new windows8. Those preferences are browser.link.open_newwindow and browser.link.open_newwindow.restriction. If a page is attempting to open a new window, these preferences allow a user to control what actually occurs. The default (in most cases) is to open a new tab instead – but these preferences allow you to open that new window, or to open the content in the same window that the link is executed in. These are the kind of tweaks that power-users love.
Up until this point, only Firefox had these tweaking capabilities. bz’s patch moved that tweaking logic “up the chain”, so to speak, which means that applications that embedded Gecko could also be tweaked like this. Pretty handy.
For the Gecko hackers reading this, this patch also introduced the nsIWindowProvider interface9.
On May 10th, 2006, “darin” landed a patch for bug 326273 that put the nsIThreadManager interface and implementation into the tree. It’s a big commit, and affected many parts of the codebase. nsIThreadManager is, not surprisingly, used to implement multi-threading and thread manipulation in Gecko. From my look at the patch, it looks like it replaces something called nsIEventQueue / nsIEventQueueService. It looks like Gecko already had some facility for multi-threading10, but nsIThreadManager looks like a different model for multi-threading.
For DocShell, this change meant modifying the way that restoring PresShell’s from history would work. Before, DocShell had a RestorePresentationEvent that extended PLEvent, which allowed it to be posted to an nsIEventQueue. Now, instead, we define an inner-class that implements nsRunnable11, and also define a weak pointer to that runnable on a DocShell.
So the way things would go is this: DocShell::RestorePresentation would get called, and this would cancel any pending RestorePresentationRunnable that the DocShell is weak-pointing to. Next, we’d instantiate a new RestorePresentationRunnable that we’d then dispatch to the main thread. This isn’t really different to what we were doing before, but it makes use of the nsIThreadManager and nsRunnable class instead of nsIEventQueue and nsIEventQueueService.
What’s interesting about this patch, DocShell-wise, is that it shows the usage of FavorPerformanceHint, which looks like a way of trading-off UI interactivity with page-to-screen time. Basically, it looks like the FavorPerformanceHint is used when restoring PresShell’s to tell the nsIAppShell, “hey – we want you to favor native events over other events for a small pocket of time so we can get this stuff to the screen ASAP”. If I’m interpreting that right, it’s a tradeoff between total time to execute and responsiveness here. “Do you want it fast, or do you want it smooth?”.
I was probably wrong about the name
In one of my past posts, I made some guesses about why DocShell was called DocShell. I thought:
I think nsDocShell was given the “shell” monicker because it did the job of taking over most of nsWebShell’s duties. However, since nsWebBrowser was now the touch-point between the embedder and embedee… maybe shell makes less sense. I wonder if we missed an opportunity to name nsDocShell something better.
But now that I look at nsIAppShell, and nsIDocShell, and nsIPresShell… I think I’m starting to understand. A while back, when I first started planning these posts, I asked blassey why he thought nsIDocShell was named the way it was, and he said he thought it might be related to the notion of a command shell – like a terminal input. From my understanding, a shell is a command interface with which one can manipulate and control something pretty complex – like the file-system or processes of a computer. I think blassey is right – I think that’s the “Shell” in nsIDocShell. I think the idea is that this interface would be the one to control and manipulate the process of loading and displaying a document. It seems obvious now, but it sure wasn’t when I started looking into this stuff.
DOM Storage (session and global), KungFuDeathGrip, friendlier search…
On May 19th, 2006, jst picked up, finished and landed a patch originally be Enn that implemented DOM Storage for bug 335540.
This patch adds two new methods to nsIDocShell – getSessionStorageForDomain and addSessionStorage. The first method is accessed in a number of cases, but most importantly when some caller reads sessionStorage or globalStorage off of the window object12.
The relationship between nsGlobalWindow and nsDocShell is brought to my attention with this patch. Here’s a fragment from an old chat I had with Ms2ger, smaug and bz, which started when I asked Ms2ger what he’d rename DocShell to.
14:11 (Ms2ger) mconley, I would call it WindowProxy 🙂
14:12 (smaug) outer window? yes, WindowProxy please
14:12 (mconley) Ms2ger: wait, outer window = docshell currently?
14:12 (khuey) what are we doing with WindowProxy?
14:13 (Ms2ger) mconley, well, no, there’s nsDocShell and nsGlobalWindow (with IsOuterWindow() true)
14:13 (Ms2ger) mconley, those are pretty much isomorphic
14:13 (mconley) I see
14:13 (bz) nsDocShell and outer nsGlobalWindow are in a 1-1 relationship
14:14 (bz) The fact that they are two separate objects is sort of a historical accident that we may want to rectify sometime
14:14 (mconley) this sounds like another post to write – how nsDocShell and nsGlobalWindow are related…
So I think nsGlobalWindow (instances of which can either be “inner” or “outer”) when it has IsOuterWindow being true, works in tandem with nsDocShell to “be” the outer window. That’s really imprecise, hand-wavey language. I’ll probably need to tighten this up in a follow-up post once somebody reads this and gives me better words to describe things13.
On May 24, 2006, smaug landed a patch to fix bug 336978. Bug 336978 was a crash caused by loading the following code in an iframe:
<html>
<head></head>
<body>
<script>
window.addEventListener("pagehide", doe, true);
function doe(e) {
var x = parent.document.getElementsByTagName('iframe')[0];
x.parentNode.removeChild(x);
}
setTimeout(doe2,500);
function doe2() {
window.location = 'about:blank';
}
</script>
</body>
</html>
What this code does is wait 500ms, and then change the location to about:blank. Changing the location causes the pagehide event to fire while we’re unloading the original page, and when we hear it, we get the host of the iframe to remove the iframe from itself.
smaug’s solution to this bug is for nsDocShell to hold a reference via an nsCOMPtr to the nsIContentViewer for the document while the pagehide event is fired. This ensures that the nsIContentViewer doesn’t get destructed before we’re truly done to it. The name we give this nsCOMPtr is “kungFuDeathGrip”. This isn’t the only place where some hold of an object is maintained with a variable called kungFuDeathGrip – check out dxr for some more uses.
I’d seen kungFuDeathGrip over the years, and I never looked closely at what it was doing. I always thought kungFuDeathGrip was some magical global function that destroyed things unequivocally, but on closer inspection, I’m pretty sure it’s really just a way of saying “this variable’s sole purpose is to hold a reference to this thing until I’m done with it.”
I think the phrase “kung fu” distracted me. I thought it did this:

Woooooo!
But it’s really more like this:

Kkkg….*gurgle*…ngahh….
On June 15th, 2006, “brettw” landed a patch for bug 245597 to make it so that anything that gets put into the AwesomeBar that isn’t parse-able as a URI automatically turns into a keyword search. That’s great! This made both the search input and the AwesomeBar useful for more users. This change occurred in docshell/base/nsDefaultURIFixup.cpp, which is, as I understand it, the central location for code that turns erroneous URIs into what the user probably intended.
nsIMutationObserver, some new about: pages…
On July 2nd, 2006, Jonas Sicking added nsIMutationObserver to the tree for bug 342062, making it possible to observe changes to the DOM within a subtree. It’s a pretty big patch, but it looks like a good chunk of it is just swapping in usage of nsIMutationObserver to replace old usage of nsIDocumentObserver (which supplied the same observations, but for an entire document instead of a subtree). Note that it’d still be a few years before DOM3 Mutation Events would be exposed for web developers to use, and after a few more years, those events were deprecated in favour of the Mutation Observer API.
On September 15th, 2006, several new Gecko-wide about: pages landed, which means they got put into the redirection map in docshell/base/nsAboutRedirector.cpp. These pages were about:buildconfig (bug 140034), about:about (bug 56061), and about:license (bug 256945). That same day, bz landed a patch to make it so that new about: pages didn’t have to have special rules hardcoded into nsScriptSecurityManager::CanExecuteScripts to execute script even if the user has script disabled. Instead, the nsAboutRedirector mapping was extended to allow a boolean for indicating that an about: page required script execution.
Simplifying DocShell, and then some spoofing and malware protection
The next interesting thing (according to me, anyhow) didn’t occur until the following May 6th, 2007. That day, bz landed a patch for bug 377303 which simplified the structure of things inside the DocShell tree.
Up until that point, there had existed both nsIDocShellTreeItem and nsIDocShellTreeNode had both existed as interfaces for interacting with nodes within a DocShell tree. I’ll quote myself from my previous post:
The (somewhat nebulous) distinction of DocShell “treeItems” and “treeNodes” is made. At this point, the difference between the two is that nsIDocShellTreeItem must be implemented by anything that wishes to be a leaf or middle node of the DocShell tree. The interface itself provides accessors to various attributes on the tree item. nsIDocShellTreeNode, on the other hand, is for manipulating one of these items in the tree – for example, finding, adding or removing children. I’m not entirely sure this distinction is useful, but there you have it.
It looks like enough was finally enough. bz didn’t go so far as to fully merge the two interfaces (though he makes a note in his patch about doing so), but instead made the (arguably more complex) nsIDocShellTreeItem interface inherit from nsIDocShellTreeNode14.
Later, on May 17th, 2007, Mats Palmgren landed a patch for bug 376562 to remove a childOffset attribute from nsIDocShellTreeItem, and instead move a setter for the childOffset to the nsIDocShell interface instead.
Reading this bug comment as well as one of Mats’ comments in the patch, it sounds as if childOffset never really worked as advertised, and was a bit of a foot-gun.15
On June 14th, 2007, bz landed a patch for bug 371360, which prevents onUnload handlers from starting any page loads. Before this, it seems that it was possible for a page do to something like this:
<html>
<body onunload="location.href = 'http://www.somesite.com';">
<a href="http://slashdot.org/">http://slashdot.org/</a>
</body>
</html>
With the result being that you could (potentially) phish a user. For example, suppose you’re a member of MySafeBank, which has a site at mysafebank.com. Suppose you’re at my seemingly innocent site totallyevil.com, and also suppose that I’ve registered a domain at rnysafebank.com (that’s an r and an n, which, if you’re not paying attention, look pretty close to a m). If you’re at my site, and I notice that you’re trying to head to mysafebank.com, I could redirect you to rnysafebank.com, which has a very similar user interface and favicon. Yadda yadda yadda, your bank info is now mine.
So bz stopped that one in its tracks by just preventing a DocShell from attempting any kind of load if we’re in the middle of an unload.
On July 3rd, 2007, johnath16 landed a patch for bug 380932 to add a new mode for about:neterror for pages suspected of serving up malware.
If you haven’t seen that page before, count yourself lucky – you’ve been surfing in safe places! This is what the page looks like (or, used to look like, anyhow):
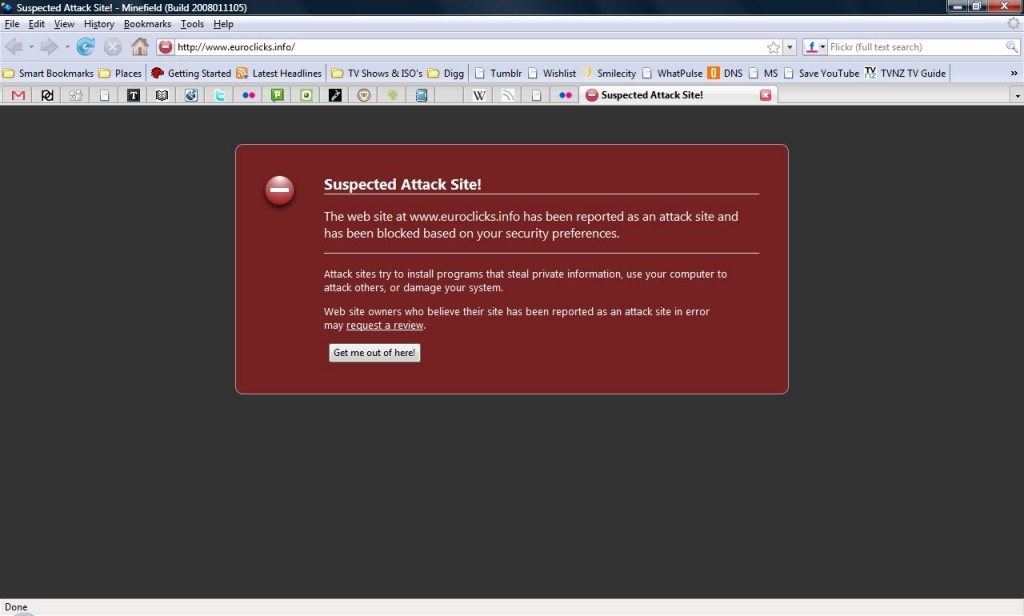
Old version of Firefox showing a Suspected Attack Site
johnath’s patch allowed an about:neterror page to have a specific CSS class associated with it as part of its URL. This allowed for the dramatic styling in the image above17.
showModalDialog
showModalDialog was a non-standard function that Microsoft introduced in Internet Explorer 418. This allows a web page to create a modal dialog that contains web content. jst landed a patch on July 26th, 2007 to implement it in Firefox as part of bug 194404. This patch made it possible for a DocShell to have a modal dialog be its parent.
showModalDialog has since been marked as deprecated on MDN, and Google Chrome have announced they will no longer support it after May of 2015. Firefox will support it until sometime after Firefox 39 on the release channel19.
about:crashes, Larry, and tab tearing
There’s a long gap in time here where nothing really interesting happens under docshell/.
Finally, on January 24th, 2008, Mossop landed a patch for bug 411490 that exposes about:crashes as a handy way of getting at the list of crash reports that have been collected.
As about:crashes is a Gecko-wide about: page, this meant once again adding an entry to the docshell/base/nsAboutRedirector.cpp map, as had been done with about:buildconfig and about:about.
On April 28th, 2008, gavin landed a patch originally by ehsan that adds a friendlier set of icons for reporting SSL errors for bug 430904.
That icon is Larry. Have you met Larry? This is Larry:

This is Larry.
Larry is the name for a series of icons that were developed to describe how secure your communications are with a particular site. You might recognize him from the airport, because he looks a lot like a customs agent or border patrol.
You can read up on Larry here on johnath’s blog.
On August 7th, 2008, bz landed a patch for bug 113934 to lay the foundation for letting users drag tabs out from a window, or drag tabs between windows. This introduced a new method to nsIFrameLoader, “swapFrameLoaders”. This method is the real key to moving tabs between windows – each <xul:browser> implements nsIFrameLoaderOwner, and the nsIFrameLoader is (yet another) thing that can load web content. This is essentially a brain transplant between two <xul:browser>’s. You can see the real guts of the brain transplant in this method of the patch.
On January 13th, in a semi-related patch, bz landed code for bug 449780 to flush the bfcache20 when swapping frameloaders. Apparently, we were storing information in the bfcache that was simply incorrect after a frameloader swap. The best way to avoid internal confusion in such a case was to just invalidate the cache.
Big gaps…
Lots of big gaps between the next few changes.
On March 18th, 2009, Honza Bambas landed a patch for bug 422526 to implement window.localStorage. localStorage was a replacement for globalStorage21 that persisted across browser restarts (unlike sessionStorage).
Note that both localStorage and sessionStorage were synchronous storage APIs. It’d take until around June 24th of 2010 before an asynchronous storage mechanism became available.
On May 7th, 2009, bz landed a patch for bug 490957 to finally get rid of nsWebShell.cpp. If you recall from my earlier blog post, that was one of Travis Bogard’s goals at the start of this whole adventure. bz’s patch essentially folds the functionality of nsWebShell into nsDocShell. The webshell/ folder remained, but just contained interfaces.
Curiously, a good chunk of nsWebShell’s functionality seemed to revolve around anchor pings, a massively unpopular “feature” that allows a website to get your browser to send a request every time you click on a link. Thankfully, this “feature” is disabled by default in Firefox22. Here’s Jorge Villalobos’s post on anchor pings. Correction (Jan 4th, 2015) – I’ve since changed my tune about anchor pings. See these three comments.
On June 29th, 2009, dbolter landed a patch for bug 467144 so that nsIMutationObserver’s, when they observe an attribute being changed, also get a copy of the old attribute as well as the new one. Actually, to be specific, it adds a callback “AttributeWillChange” to include the old attribute. This fires before the “AttributeChanged” callback.
A day later, bsmedberg landed a massive patch to implement remote tabs. There’s no bug number in the commit message, but this is clearly part of the Electrolysis efforts that were just starting up around this time. Remote tabs means browsers that run in different processes, which is the overall goal of Electrolysis, and (possibly unbeknownst to bsmedberg at the time) a foundational piece for Fennec (Firefox for Android)23.
On October 3rd, 2009, vvuk landed about:memory for bug 515354, a key piece of the war against high-memory consumption in Firefox (a.k.a. MemShrink). This is very similar to the about:crashes page that Mossop landed back in 2008.
And finally…
On January 7th, 2010, smaug landed a patch for bug 534226 to remove support for multiple PresShell’s. PresShell stands for “Presentation Shell”, and as I understand it, is the primary interface to the “frame tree”24.
It looks like, up until this point, Gecko had the ability to have multiple frame trees per content tree. I’m not entirely sure what the point of that was, but the capability was there. smaug’s patch simplifies everything by making sure a document has only a single, primary PresShell. This removes a lot of iteration and management code for those multiple PresShell’s, which is nice.
And last, but not least, on June 30th, 2010, Benjamin Stover landed a patch for bug 556400 which made it so that visits to webpages are recorded asynchronously in Places. It looks like this patch takes I/O off the main-thread, so it gets a big thumbs-up from me.
Essentially, this patch adds new asynchronous write methods to the History service, and then makes nsDocShell use those methods on webpage visits. nsDocShell falls back to the synchronous methods of nsIGlobalHistory2 if, for some reason, it can’t get at the History service and its asynchronous methods.
Phew!
Did you make it? Are you still with me? I know it might feel like this:

everyone is a winner
but I think we’re making real progress here. I think we’re learning important stuff about the history of Firefox, and changes that have occurred in some of its core functionality over time.
So to sum, that, to me, was the most interesting stuff to happen in and around docshell/ from 2005-2010. There might have been other neat stuff in there, but it didn’t catch my eye when I was browsing commit messages.
There’s still much to do – I have to look at commits from 2011 to 2014. After that, I’m planning on doing a line-by-line code review / walkthrough of nsDocShell.cpp, and then I’d like to try to summarize my findings and any recommendations I’ve put together from my time studying this stuff.
Hold tight!
{kind=link}