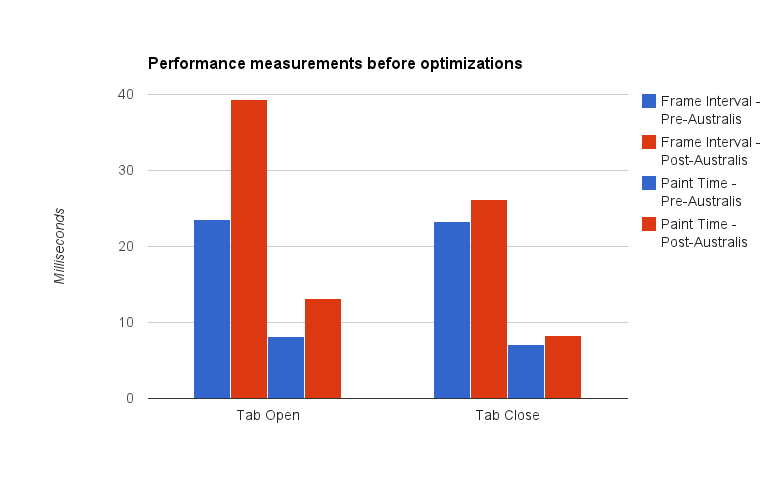
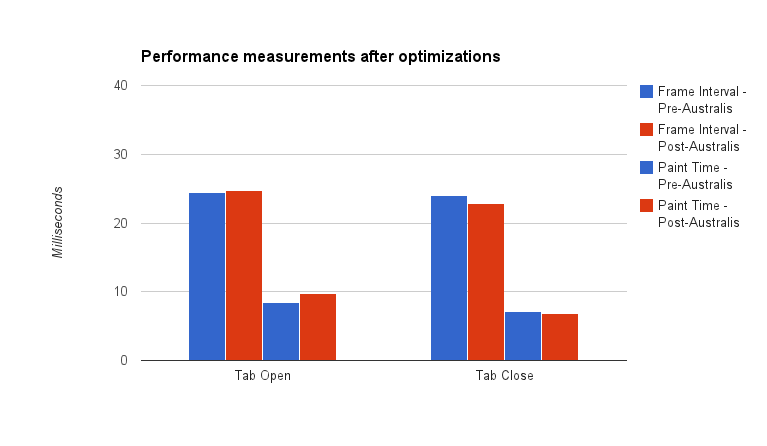
In 2006, Smart Bear software teamed up with the MeetingPlace development group at Cisco Systems, and over 10 months, produced the “largest-ever case study of its kind” on a “light-weight code review process”.
The results of the study can be found in the free book “Best Kept Secrets of Peer Code Review”.
They can also be found in one of the sample chapters that they’ve put on the site. You can read the study right here, if you’re interested.
Here are my thoughts on the chapter…
First of all, my guard is up a bit. This all seems a bit like a sales pitch, since the software that Cisco ends up using is Smart Bear’s own Code Collaborator. I’m reading the first paragraph, and already I know how it ends – “everybody is happy, the software is improved dramatically, so you should buy Code Collaborator”. Something like that. I’ll be happy when I see some solid data, some numbers, some graphs…
Ok, I’m in at page 54 – they’re talking about how data was collected, and how they pared it down to get the most meaningful results. This is good. This sounds like science, and not a sales pitch. Nice.
The next thing the study talks about is the rate that lines of code (LOC) are analyzed at – the LOC inspection rate. The data they’ve collected shows no discernible 1-1 correlation between the LOC inspection rate, and the amount of code to inspect. There were rare exceptions where a reviewer would seem to have such a correlation, but these reviewers tended to be novices who had not participated in many reviews before. Analyzing the LOC inspection rates by code authors (those who are having their code reviewed) also failed to show any correlations. In fact, there were several cases where separate reviewers took widely varied amounts of time on the same chunk of code under review.
So this leaves us with no clear answer on what factors play a part in LOC inspection rate.
The study then begins to discuss the effectiveness of the reviews, and whether or not slow reviews reveal more “defects” (where a defect is defined as any change to the code that wouldn’t have happened without the review). Because defect data from the Code Collaborator database was not considered wholly reliable (see pages 62 and 63 if you want to know why), 300 reviews were randomly plucked from the original 2500, and the discussions in each one were analyzed to gather the defect statistics.
The study then introduces the concept of “defect density”, which is a ratio of the number of defects detected per 1000 lines of code (referred to henceforth as kLOC).
I’ll skip right to some results:
Our reviews had an average 32 defects per 1000 lines of code. 61% of the reviews uncovered no defects; of the others the defect density ranged evenly between 10 and 130 defects per kLOC.
I’m surprised that 61% of the reviews found no defects. That’s remarkably high, in my opinion. True, it’s only a sample of 300 reviews, but still, my instincts were expecting a significantly lower number.
An even more interesting result, is that defects found (and therefore, review effectiveness) dropped off for large amounts of code to review. The study notes that:
Anything below 200 lines produces a relatively high rate of defects, often several times the average.
So there seems to be a sweet spot. I wonder if this is a factor in what was causing the surprising high number of defect-less reviews in that sample of 300. Perhaps many of those reviews were for large sections of code. Or perhaps they’re for reviews that involve only a single line of code. The study doesn’t go into this.
What the study does go into, is a general guideline for limiting the time that code reviews take. Their study noted a stark dropoff in review effectiveness after about an hour. Totally understandable – I think an hour reviewing someone else’s code would probably be my limit before I started getting distracted.
The study then goes on to suggest that the “slower is better” approach to reviewing code is the right idea:
Reviewers slower than 400 lines per hour were above average in their ability to uncover defects. But when faster than 450 lines/hour the defect density is below average in 87% of the cases.
So already there are some guidelines: try to review something around 200 LOC, take your time, but don’t go over an hour. This is useful information.
The study then goes into a test of a slight modification of how reviews are performed: before submitting code for review, the author should annotate the code, describing how the changes are structured, why they were coded the way they were coded, etc. This has a dual-benefit: it gives reviewers some clues at how to look at the code (while, hopefully, maintaining the distance they need to do a good job), and it also has the added benefit of getting the author to go over their code again to weed out obvious defects.
So, some reviews were carried out in this fashion. Here’s what they found:
First, for all reviews with at least one author preparation comment, defects density is never over 30; in fact the most common case is for there to be no defects at all! Second, reviews without author preparation comments are all over the map [in terms of defect density] whereas author-prepared reviews do not share that variability.
The study gives two possible conclusions for these results:
- Authors gave their code such a thorough look while annotating them, that most defects were eliminated right off the bat. I’m…skeptical of this conclusion.
- Since authors were explaining, or defending their changes, this sabotaged the reviewers ability to do their job effectively.
I find myself believing the second conclusion more, simply from experience: if somebody is guiding me through things, suddenly I’m in the passenger seat, and I’m less inclined to disagree with a change if their explanation or defense sounds solid.
However, Smart Bear disagrees:
A survey of the reviews in question show the author is being conscientious, careful, and helpful, and not misleading the reviewer. Often the reviewer will respond or ask a question or open a conversation on
another line of code, demonstrating that he was not dulled by the author’s annotations.
…
…we believe that requiring preparation will cause anyone to be more careful, rethink their logic, and write better code overall.
I’d like to see their data on this. In particular, I’d like to see how often reviewers detected defects in lines of code that the author had annotated. Unfortunately, this data is not provided in the study.
In the last few pages, the study notes that while review size has a detrimental impact on defect density (the number of defects reviewers found per kLOC), there seemed to be a fixed rate on the number of defects found per hour. While this seems at odds with the original discovery that smaller reviews are more effective, they note:
Although the smaller reviews afforded a few especially high rates, 94% of all reviews had a defect rate under 20 defects per hour regardless of review size.
…
…the take-home point from Figure 22 is that defect rate is constant across all the reviews regardless of external factors.
So, assume that a reviewer has a steady defect detection rate, but that this rate drops off after about an hour. Given a small section of code, of course the number of defects detected will be high. And given a large chunk of code, of course the defects will be more spread out.
It’s the steady defect detection rate that bothers me – you would imagine that the detection rate would depend on the quality of the code and also on the experience of the reviewer. But I guess, according to this study, it doesn’t.
And so, the study goes into its conclusions. I can’t really do much better summarizing the first conclusions for you than they did, so I’ll just regurgitate:
- LOC under review should be under 200, not to exceed 400. Anything larger overwhelms reviewers and defects are not uncovered.
- Inspection rates less than 300 LOC/hour result in best defect detection. Rates under 500 are still good; expect to miss significant percentage of defects if faster than that.
- Authors who prepare the review with annotations and
- explanations have far fewer defects than those that do not. We presume the cause to be that authors are forced to self-review the code.
- Total review time should be less than 60 minutes, not ex- ceed 90. Defect detection rates plummet after that time.
- Expect defect rates around 15 per hour. Can be higher only with less than 175 LOC under review.
- Left to their own devices, reviewers’ inspection rate will vary widely, even with similar authors, reviewers, files, and size of the review.
Given these factors, the single best piece of advice we can give is to review between 100 and 300 lines of code at a time and spend 30-60 minutes to review it. Smaller changes can take less time, but always spend at least 5 minutes, even on a single line of code.
The study then goes into the differences in effectiveness between heavy-duty Fagan-esque code reviews, and the lightweight style of code review that took place at Cisco. While some of their results from their study exactly match results from studies on heavyweight code reviews (time to spend on a review, when effectiveness drops off), there were some stark differences too.
For example, in the lightweight study, defect detection rate using Smart Bear was 7 times faster than the average rate found across four studies of traditional code review methods. Sounds like we’re getting into that sales-pitch part…
The study then admits that there was no experiment control – reviews using heavyweight techniques weren’t carried out in parallel with the Code Collaborator study, so comparisons of their effectiveness on the MeetingPlace software have little-to-no data to work with.
In the end, their conclusion is that lightweight code review is just as effective as the traditional methods, while being remarkably faster to boot. I’d like to see more evidence to back up the comparison on effectiveness, but faster seems more than plausable (Fagan inspections involve very lengthy meetings, so I’ve read).
Smart Bear agrees with my last point on effectiveness comparison, and notes that future study should be conducted where the same set of code is analyzed using both heavy and lightweight methods.
They finish it off with an invitation to software development shops to contact Smart Bear if they’d like to be involved in such a study.
So that’s the gist of it.